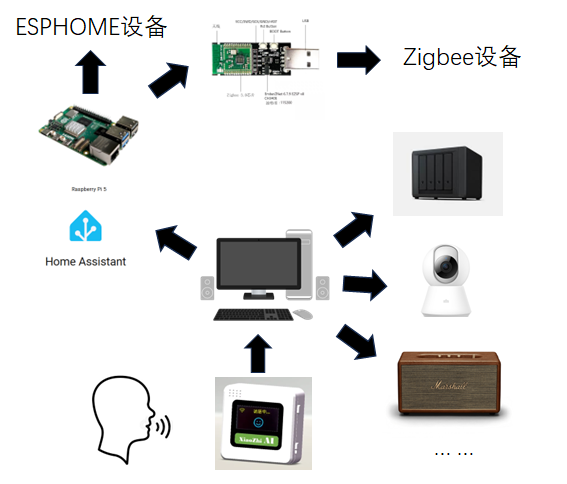
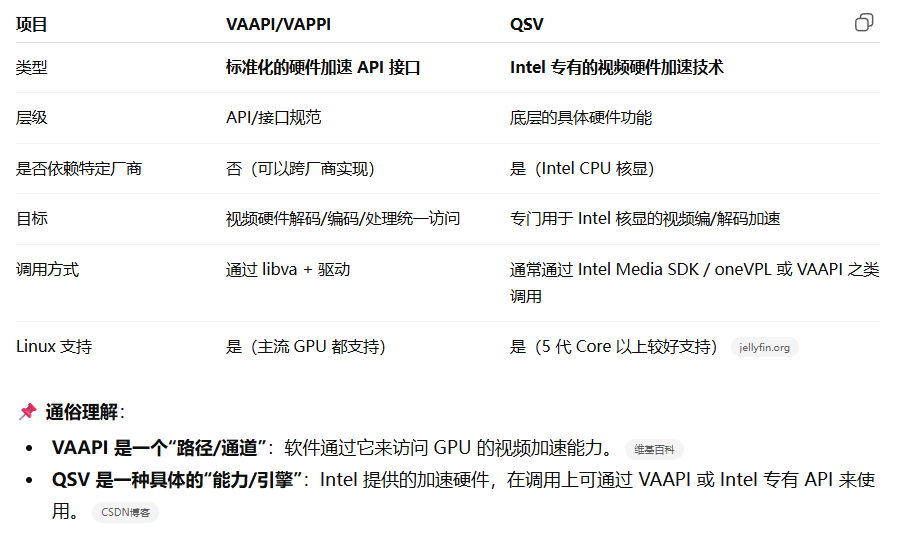
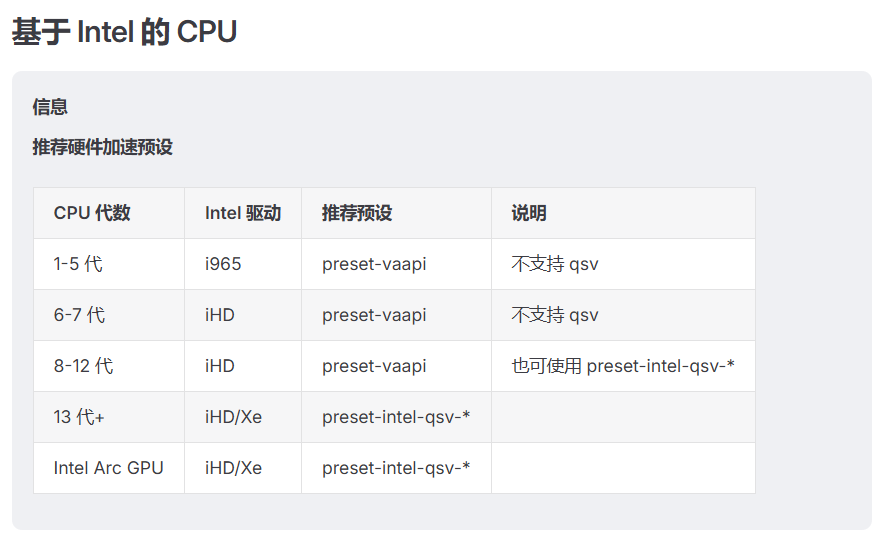
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
| #!/usr/bin/env python3
# -*- coding: utf-8 -*-
import json
import os
import re
from datetime import datetime, timezone
from email.utils import format_datetime
from urllib.parse import quote
import requests
import xml.etree.ElementTree as ET
PODCAST_URL = "https://www.xiaoyuzhoufm.com/podcast/60de7c003dd577b40d5a40f3"
# 音频/封面/XML 都放这里(U 盘)
OUT_DIR = "/mnt/usb_share/podcast/zaokafei"
XML_PATH = os.path.join(OUT_DIR, "zaokafei.xml")
# 你这台 ThinkPad 的 HTTP 服务地址(用你确认的 IP)
BASE_HTTP = "http://192.168.31.75:10086"
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)",
}
def get_next_data(url: str) -> dict:
"""从小宇宙网页里解析 __NEXT_DATA__ JSON"""
html = requests.get(url, headers=HEADERS, timeout=30).text
m = re.search(
r'<script id="__NEXT_DATA__" type="application/json">(.*?)</script>',
html,
re.S,
)
if not m:
raise RuntimeError("没找到 __NEXT_DATA__,小宇宙页面结构可能变了")
return json.loads(m.group(1))
def sanitize_filename(name: str) -> str:
"""文件名安全化(保留中文,但去掉不允许字符,避免太长)"""
name = re.sub(r'[\\/:*?"<>|]', "_", name).strip()
name = re.sub(r"\s+", " ", name)
return name[:160] if len(name) > 160 else name
def parse_pubdate_to_utc(pub: str) -> datetime:
"""
解析小宇宙 pubDate(通常 ISO8601,可能带 Z)
返回 timezone-aware UTC datetime
"""
try:
if pub.endswith("Z"):
dt = datetime.fromisoformat(pub.replace("Z", "+00:00"))
else:
dt = datetime.fromisoformat(pub)
if dt.tzinfo is None:
dt = dt.replace(tzinfo=timezone.utc)
return dt.astimezone(timezone.utc)
except Exception:
# 解析失败就用当前时间兜底(不影响下载,只影响 pubDate)
return datetime.now(timezone.utc)
def download_file(url: str, path: str):
"""流式下载,先写 .part 再原子替换"""
r = requests.get(url, headers=HEADERS, stream=True, timeout=180)
r.raise_for_status()
tmp = path + ".part"
with open(tmp, "wb") as f:
for chunk in r.iter_content(chunk_size=1024 * 256):
if chunk:
f.write(chunk)
os.replace(tmp, path)
def ensure_xml_exists():
if os.path.exists(XML_PATH):
return
raise RuntimeError(
f"找不到 {XML_PATH}\n"
f"请先把 zaokafei.xml 放到 {OUT_DIR} 下(至少包含 <rss><channel>...</channel></rss>)"
)
def xml_has_guid(root: ET.Element, guid: str) -> bool:
for item in root.findall("./channel/item"):
g = item.findtext("guid")
if g and g.strip() == guid:
return True
return False
def add_item_to_xml(
title: str,
guid: str,
pub_dt_utc: datetime,
enclosure_url: str,
length_bytes: int,
):
"""
把新一期插入到 XML 的最前面(靠前显示)
仅写入最必要字段:title/pubDate/guid/enclosure
"""
ET.register_namespace("itunes", "http://www.itunes.com/dtds/podcast-1.0.dtd")
tree = ET.parse(XML_PATH)
root = tree.getroot()
channel = root.find("channel")
if channel is None:
raise RuntimeError("XML 里没找到 <channel>")
if xml_has_guid(root, guid):
print("XML 已存在该期 guid,跳过写入:", guid)
return
item = ET.Element("item")
t = ET.SubElement(item, "title")
t.text = title
pub = ET.SubElement(item, "pubDate")
pub.text = format_datetime(pub_dt_utc) # RFC 2822
g = ET.SubElement(item, "guid", attrib={"isPermaLink": "false"})
g.text = guid
ET.SubElement(
item,
"enclosure",
attrib={
"url": enclosure_url,
"length": str(length_bytes),
"type": "audio/mp4",
},
)
# 插到最前面:放在第一个 item 前
first_item = channel.find("item")
if first_item is None:
channel.append(item)
else:
children = list(channel)
idx = children.index(first_item)
channel.insert(idx, item)
tree.write(XML_PATH, encoding="UTF-8", xml_declaration=True)
print("已更新 XML:", XML_PATH)
def main():
os.makedirs(OUT_DIR, exist_ok=True)
ensure_xml_exists()
data = get_next_data(PODCAST_URL)
podcast = data["props"]["pageProps"]["podcast"]
latest = podcast["episodes"][0]
eid = latest["eid"]
title = latest["title"]
pub_raw = latest.get("pubDate", "")
# 音频 URL 兼容两种字段
audio_url = (
latest.get("media", {}).get("source", {}).get("url")
or latest.get("enclosure", {}).get("url")
)
if not audio_url:
raise RuntimeError("没找到 media.source.url / enclosure.url")
pub_dt_utc = parse_pubdate_to_utc(pub_raw)
date_str = pub_dt_utc.strftime("%Y-%m-%d")
safe_title = sanitize_filename(title)
filename = f"{date_str} - {safe_title}.m4a"
out_path = os.path.join(OUT_DIR, filename)
# 先判断 XML 是否已经有 guid:有的话可以直接结束(更省事)
# 但为了保险(避免 XML 手动改动),我们仍然会检查文件是否存在。
print("最新一期:", title)
print("EID:", eid)
print("发布时间(UTC):", pub_dt_utc.isoformat())
print("音频:", audio_url)
if os.path.exists(out_path):
print("文件已存在,跳过下载:", out_path)
else:
download_file(audio_url, out_path)
print("下载完成:", out_path)
# URL 编码文件名(中文/空格更稳)
enclosure_url = f"{BASE_HTTP}{quote('/' + filename)}"
length_bytes = os.path.getsize(out_path)
add_item_to_xml(
title=title,
guid=eid,
pub_dt_utc=pub_dt_utc,
enclosure_url=enclosure_url,
length_bytes=length_bytes,
)
if __name__ == "__main__":
main()
|